
Arquitetura do Oracle Database 23ai: Visão Sistêmica da Instância e do Banco de Dados
- Dennis Tavares

- 17 de fev.
- 6 min de leitura
Não tem como falar de banco de dados Oracle sem conhecer a sua arquitetura, neste primeiro resumo, trago um breve compilado do conteúdo oficial ao analisar a separação conceitual entre instância e banco de dados aprofundando sob a perspectiva da arquitetura interna do kernel Oracle, estabelecendo base técnica para compreensão detalhada de processamento, persistência física, controle transacional, sincronização e recuperação.
A arquitetura do Oracle Database é implementada por camadas internas do kernel que operam sobre memória compartilhada e estruturas físicas persistentes. A instância é o conjunto de estruturas de memória e processos background responsáveis por manipular o banco de dados, que por sua vez é o conjunto de arquivos físicos persistentes. A interação entre esses domínios é mediada por mecanismos internos estruturados nas camadas KCB (Kernel Cache Buffer), KCR (Kernel Cache Redo), KGL (Kernel Generic Library), KCC (Kernel Cache Controlfile) e KTU (Kernel Transaction Undo), além das camadas de sincronização KGX/KSL e instrumentação KSR. No Oracle 23ai essa arquitetura permanece consistente com 12c e 19c, preservando o modelo de SGA, PGA e processos background.

Durante o processo de startup em NOMOUNT, o kernel da instância inicializa as estruturas fundamentais da SGA (System Global Area). A alocação de memória é realizada por mecanismos internos de gerenciamento de heap, responsáveis por organizar os diversos componentes de SGA de forma segmentada e independente.
O Database Buffer Cache é responsável por armazenar cópias de blocos de dados em memória, reduzindo operações físicas de I/O. Internamente, o cache mantém metadados para cada buffer de memória, incluindo identificadores do bloco (file#, e block#), estado do buffer (por exemplo, livre, consistente, corrente), informações de consistência e controle de acesso concorrente.
Embora essas estruturas sejam baseadas em tabelas fixas internas (como x$), a Oracle recomenda que análises operacionais e diagnósticos utilizem views dinâmicas de desempenho (V$/GV$), que são suportadas e estáveis entre versões.
Como podemos ver na consulta abaixo, todos os blocos estão atualmente no Buffer Cache, são exibidos em memória e não houve necessidade de I/O físico no momento da consulta. Significa que são blocos recentemente acessados.
select
o.owner,
o.object_name,
o.object_type,
bh.file#,
bh.block#,
bh.status
from v$bh bh
join dba_objects o
on bh.objd = o.data_object_id
and o.owner = 'HR'
where rownum <= 10;
Podemos também evidenciar blocos residentes no cache. Representados graficamente com buffer headers encadeados por hash chains protegidas por latches cache buffers chains.
01 - Evidência de contenção no latch CBC
select
child#,
gets,
misses,
sleeps,
round(100 * misses / nullif(gets,0), 4) as miss_pct,
rpad('█', least(50, misses), '█') as contention_graph
from v$latch_children
where name = 'cache buffers chains'
order by misses desc
fetch first 10 rows only;
Se houver misses ou sleeps elevados são evidência de hot chains.
02 - Evidência de Blocos Mais Acessados no Cache
select
file#,
block#,
count(*) as copies_in_cache,
rpad('█', least(50, count(*)), '█') as residency_graph
from v$bh
group by file#, block#
having count(*) > 1
order by copies_in_cache desc
fetch first 10 rows only;
Blocos com múltiplas cópias podem indicar (RAC, CR clones ou Alta concorrência).
03 - Correlacionar com objeto
select
o.owner,
o.object_name,
bh.file#,
bh.block#,
count(*) as buffers
from v$bh bh
join dba_objects o on bh.objd = o.data_object_id
group by o.owner, o.object_name, bh.file#, bh.block#
order by buffers desc
fetch first 10 rows only;
A substituição de blocos é gerenciada por listas internas parcialmente LRU, protegidas por latches implementados na camada KGX. Esses latches são estruturas KSL que operam com spin e eventual sleep, registrando estatísticas em X$KSLLT. A contenção pode ser analisada com:
select name, gets, misses, sleeps
from v$latch
where name
like 'cache buffers%';
O Shared Pool é administrado pela camada KGL. Objetos SQL são representados por handles KGLHD e heaps associados. Cada cursor possui child cursors diferenciados por ambiente de otimização e metadados de bind.
A sincronização é realizada predominantemente por mutexes. Estruturas internas podem ser observadas via:
select kglnaobj, kglobtyp
from x$kglcursor
where rownum <= 10;
O Redo Log Buffer é controlado pela camada KCR. Cada alteração em bloco gera change vectors encapsulados em redo records formatados pelo KCRF. O log buffer é circular e protegido por redo allocation latches e redo copy latches. Sessões competem por espaço ao alocar redo entries. Eventos como latch: redo allocation e log buffer space refletem essa concorrência.
select event, total_waits
from v$system_event
where event
like 'log buffer%';
select name, value
from v$sysstat
where name = 'redo buffer allocation retries';
Se ambos valores retornarem 0, significa que não houve pressão no log buffer.
Para validar contenção no Log Buffer, pressão de alocação de Redo e validar a estrutura interna podemos executar os seguintes comandos select.
01 - Validar Contenção no Log Buffer
select
event,
total_waits,
time_waited,
average_wait
from v$system_event
where event in (
'log buffer space',
'latch: redo allocation',
'latch: redo copy'
)
order by total_waits desc;
02 - Validar Pressão de Alocação de Redo
select
name,
value
from v$sysstat
where name in (
'redo buffer allocation retries',
'redo entries',
'redo size'
);
03 - Validar Estrutura Circular (Indiretamente)
O buffer é circular e drenado pelo LGWR. Podemos validar via:
select
name,
value
from v$sysstat
where name in (
'redo writes',
'redo blocks written',
'redo write time'
);
04 - Visualização estrutural interna
Isso mostra a alocação real do log buffer dentro da SGA.
select
component,
current_size,
user_specified_size
from v$sga_dynamic_components
where component like '%log buffer%';

Como o objetivo aqui é abordar a arquitetura não iremos aprofundar neste tema, mas é possível criar um laboratório controlado para gerar contenção real e demonstrar estes waits.
O banco de dados físico é estruturado sob controle da camada KCC. O control file mantém descritores fixos para datafiles e redo logs. Estruturas como X$KCCDI e X$KCCLE expõem esses registros. Cada datafile possui header contendo checkpoint SCN persistido.

O SCN (System Change Number) é o marcador lógico global de ordenação transacional. No commit, o SCN é atribuído e o LGWR grava redo correspondente, caracterizando o evento log file sync. O SCN atual pode ser observado com:
select current_scn from v$database;
Checkpoints são coordenados pelo CKPT, que atualiza headers de datafiles e control file com o checkpoint SCN. O DBWn grava buffers sujos cuja modificação é anterior ao target checkpoint SCN. A checkpoint queue é mantida pelo KCB.
Linha do tempo técnica de falha
T0 – Transações geram redo; blocos modificados permanecem no buffer cache.
Criado a tabela de hr.recovery_test

Inserido registros na tabela e não efetuado o commit.


Validando geração de redo:

Percebe-se que os redos estão sendo gerados e os blocos sujos estão no buffer cache.

T1 – Commit força LGWR a gravar redo; SCN é confirmado.
Efetuado commit.

Captura de SCN.

Percebemos que o LGWR gravou redo e o commit foi confirmado.

T2 – Falha de instância ocorre antes do flush completo de blocos sujos.

T3 – Startup detecta último checkpoint SCN registrado.
Inicio o banco de dados em modo normal.

Podemos observar durante o startup que o Oracle reconheceu e está iniciando o recovery.

Agora podemos comparar com o SCN anterior.

T4 – SMON executa roll forward aplicando redo desde o checkpoint.
Durante o startup o Oracle aplica o redo.

Redo aplicado desde checkpoint.

T5 – Rollback aplica undo para transações não confirmadas.
Agora vamos simular o rollback de transações que não sofreram commit antes do crash.
Inserindo 1 registro na nossa tabela e não efetuar o commit.

Encerrar novamente o banco de dados com shutdown abort.
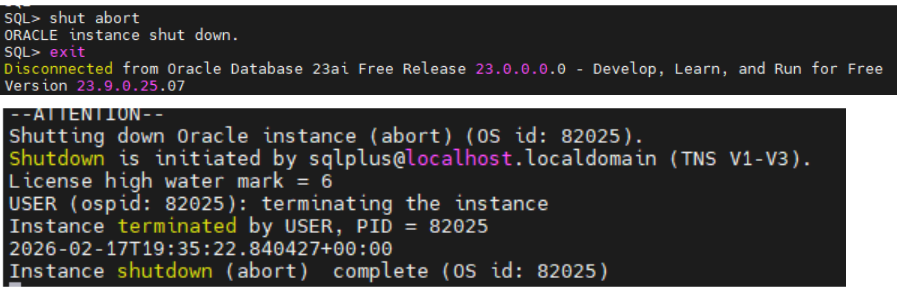
Observamos que o banco de dados encontrou inconsistência e efetuou o recovery.

Após a execução do select abaixo podemos confirmar que o registro ‘UNCOMMITTED’ não existe, o undo foi aplicado e que foi efetuado o rollback da transação que não sofreu commit.

T6 – Banco retorna a estado consistente.
Validamos a consistência dos dados.

O banco está aberto com o status open.

Aqui temos a evidência arquitetural de que o redo protege as transações que sofreram commit, que os blocos sujos não precisam estar no disco, o recovery utiliza o checkpoint SCN e o Oracle também garante a consistência via redo + undo.
O gerenciamento dessas transações é conduzido pela camada KTU. Estruturas X$KTUXE expõem entradas da transaction table.
select ktuxeusn, ktuxeslt, ktuxesta
from x$ktuxe
where rownum <= 10;
A wait interface é implementada pela camada KSR. Eventos registrados em V$SESSION e V$SESSION_EVENT refletem interação com recursos protegidos por latches, mutexes ou operações de I/O.
select sid,
event,
state
from v$session
where state='waiting';
A arquitetura interna do Oracle Database revela um sistema modular no qual KCB gerencia buffers e consistência de blocos, KCR gerencia redo e durabilidade, KGL administra objetos compilados e cursores, KCC mantém metadados estruturais persistentes e KTU controla transações e undo. As views V$ projetam estruturas X$ residentes na SGA. A instância manipula estruturas voláteis e coordena escrita física; o banco de dados preserva estados consistentes baseados em SCN, redo e checkpoints.
Neste post exploramos a arquitetura interna do Oracle Database sob a perspectiva do kernel, conectando estruturas fixas (X$) aos principais subsistemas responsáveis pelo processamento de dados. Analisamos o papel dos componentes KCB, KCR e KGL, os mecanismos de sincronização via latches e mutexes, o controle e propagação do SCN, além da dinâmica de checkpoints e do fluxo completo de instance recovery. O objetivo foi ir além da visão conceitual, correlacionando teoria e evidências práticas para compreender como o Oracle garante consistência, desempenho e recuperação em cenários críticos.
Referências:
Espero que seja de bom proveito e nos vemos no próximo post.
Um abraço e Hands on!



Comentários